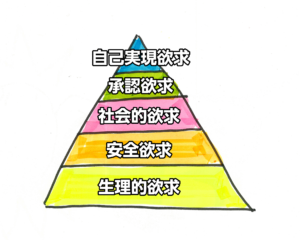
漢数字を調べる

漢数字を「一」から「十」までをエクセルで並べてみると、数値順にはなりません。
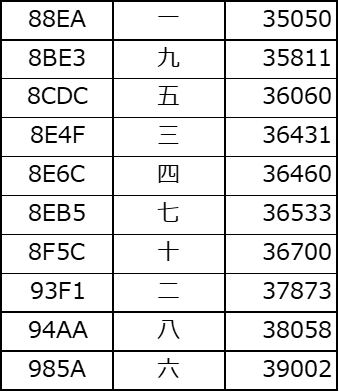
「一」の部首は「一」
「二」の部首は「二」
「三」の部首は「一」
「四」の部首は「口」(くにがまえ)
「五」の部首は「二」
「六」の部首は「八」
「七」の部首は「一」
「八」の部首は「八」
「九」の部首は「乙」(おつ)
「十」の部首は「十」
というように部首で分かれているため、並ばせると「値」の通りには並びません。
このことは、漢数字を使ったラベルなどでは、データをソートかけると期待通りには並びません。組織名称で「第一」「第二」「第三」のような部門は、「一、三、二」のような並びになってしまいますが、通常は組織コードがついているので問題は発生しないことと思います。
英語圏の人なら「部首別」という発想を持つことは出来ないと思います。中国では、漢数字をどのようにコード化しているのかは不明です。
アメリカが発祥のファイリングでは、個別の文書を厚紙に挟んで縦にしてキャビネット(バーチカル)に収納する。その時に探しやすいように見出しを付けます。その見出しは、英語圏ならアルファベットか数字で意味を成しますが、日本語の場合だと「漢字」を使わざるを得ません。
しかし、漢数字のように、そんなに簡単な配列を組むことはできません。文字コード順では人間的意味を成しません。同様に画数も意味を成しません。部首も同様です。
読みは音読みと訓読みがあって、これも並べるとなると万人に理解を得られるようには思えません。そのうえ、多様な読み方があるわけですから、文字を使った配列は破綻せざるを得ないでしょう。
データという観点からすれば英数字を配列する場面では単純な仕組みにすることができますが、だからといって漢字が劣っているわけでは全くありません。それを如実に示しているが「アイコン」だと言えます。シンボルにすることで意味を与えていますが、そもそも多くの漢字にはシンボル性が具備されているとも言えます。